Att konvertera tal till text har aldrig varit enklare, tack vare Hugging Faces tal-till-text-modeller. Oavsett om du transkriberar intervjuer, genererar undertexter eller utvecklar AI-drivna applikationer, erbjuder Hugging Face toppmodern taligenkänning som drivs av avancerade maskininlärningsmodeller. Den bästa delen? Den är mycket anpassningsbar, så att du kan finjustera modeller för bättre noggrannhet och prestanda baserat på dina specifika behov.
I den här guiden går vi igenom hur du ställer in och använder tal-till-text Hugging Face API , utforska dess anpassningsalternativ och diskutera praktiska användningsfall. Men vad händer om du behöver ett enklare alternativ? Oroa dig inte – vi kommer också att introducera ett lättanvänt tal-till-text-verktyg som gör jobbet enkelt. Oavsett om du är en utvecklare, innehållsskapare eller affärsproffs hjälper den här guiden dig att hitta den bästa tal-till-text-lösningen för ditt arbetsflöde, fortsätt läsa.
I den här artikeln
- Så fungerar det att krama ansikte-tal till text
- Ställa in Hugging Face-tal till text
- Ett enklare alternativ:Automatisk tal-till-text med Filmora
- Vilket verktyg är bäst
Del 1:Hur att krama ansiktstal till text fungerar
Hugging Face Speech-to-Text är en fantastisk funktion i Hugging Face Transformers-biblioteket som låter dig förvandla talade ord till skriven text med hjälp av förtränade modeller. Den använder avancerad automatisk taligenkänningsteknik (ASR) för att transkribera tal. Med transformatorbaserade arkitekturer som Wav2Vec2 bearbetar systemet ljuddata och omvandlar det till text. Och det gör det med stor noggrannhet.
En av de saker som gör Tal-till-text i Hugging Face sticker ut är dess pipeline-integration som gör det superenkelt för utvecklare. Med bara några rader kod kan du bearbeta ljudfiler och få textavskrifter. Den har också förutbildade modeller för flera språk och talscenarier så att den är anpassningsbar för många användningsfall.
Tal-till-text-processen följer en steg-för-steg-sekvens för att säkerställa korrekt transkription:
- Ljudindata:Du tillhandahåller en ljudfil att bearbeta.
- Funktionsextraktion:Systemet extraherar talfunktioner, log-mel filterbanker. Detta hjälper till att analysera ljudmönster.
- Modellinferens:En förtränad transformatormodell bearbetar funktionerna och genererar texttokens som representerar talade ord.
- Textutdata:Modellen konverterar dessa tokens till en textavskrift.
Hugging Face-tal-till-text-modeller, särskilt SeamlessM4T-v2, förbättrar effektiviteten genom att implementera en dubbel sekvens-till-sekvens (seq2seq) ramverk. Den har separata tal- och textkodare, samt en HiFi-GAN-vokoder, som förbättrar kvaliteten på den genererade rösten. Det här är ett användbart verktyg för taligenkänning och automatisering, med applikationer inklusive virtuella assistenter, livetextning, transkriptionstjänster och röstsökning.
Del 2:Ställa in Hugging Face Speech till text
Nedan finns en steg-för-steg-guide om hur du ställer in för att använda tal som kramar ansikte till text:
Steg 1:Skapa ett Hugging Face-konto

Det första du behöver är ett konto på Hugging Face. Genom att skapa ett konto får du tillgång till förutbildade modeller och API:er. Om du inte redan har ett konto;
- Gå till webbplatsen för hugging face
- Klicka på Registrera dig
- Ange dina uppgifter och skapa ett konto
- När du har loggat in går du till dina profilinställningar
- Hitta åtkomsttokens och skapa en ny token (välj "Skriv" som behörighetsnivå)
Denna token hjälper dig att ansluta till Hugging Face från din kod.
Steg 2:Installera nödvändiga bibliotek
Nästa sak du behöver göra är att installera alla bibliotek som du behöver. För att göra detta, öppna din terminal eller kommandotolken och skriv:
pip installera transformatorer datauppsättningar torchaudio librosa ljudfil
Transformers är till för att ladda Hugging Face-modeller, torchaudio hjälper till att bearbeta ljuddata, medan librosa och ljudfiler hjälper till att ladda och ändra ljudfiler.
Steg 3:Ladda modellen
När du har installerat alla nödvändiga bibliotek är nästa sak du behöver göra att ladda tal-till-text-modellen. Du kan använda Wav2Vec2 eftersom det är en av de bäst förutbildade modellerna för taligenkänning.
från transformatorer importera Wav2Vec2ForCTC, Wav2Vec2Processor
importera ficklampa
# Ladda modellen och processorn
model_name ="facebook/wav2vec2-large-960h"
processor =Wav2Vec2Processor.from_pretrained(model_name)
model =Wav2Vec2ForCTC.from_pretrained(model_name)
Steg 4:Konvertera ljud till text
Du måste förbereda din ljudfil så att modellen kan förstå den. För att uppnå detta måste du ladda ljudet till din programvara. Se sedan till att den är i rätt format så att modellen kan bearbeta den på rätt sätt. Du kör den genom modellen för att omvandla talet till text.
importera bibliotek
#Ladda en ljudfil och konvertera till 16kHz
def load_audio(file_path):
audio, sr =librosa.load(file_path, sr=16000)
returnera ljud
audio_file ="example.wav"
audio_input =load_audio(audio_file)
Bearbeta ljudingången så att modellen kan läsa den
input_values =processor(audio_input, return_tensors="pt", sampling_rate=16000).input_values

Obs:För större projekt erbjuder Hugging Face en API-slutpunkt som låter dig behandla tal på distans utan att hantera modellen på din egen enhet. Registrera dig helt enkelt för ett Hugging Face-konto, skaffa en API-nyckel och skicka ljudfiler via en enkel API-förfrågan.
Hur man anpassar tal-till-text-modeller
Om du vill att din modell för tal-till-text Hugging face ska fungera bättre måste du finjustera den. Grundmodellen är bra, men den kanske inte förstår vissa accenter, bakgrundsljud eller speciella ord. Att träna den med dina egna data hjälper den att lära sig och förbättra, vilket gör den mycket mer exakt för dina behov. Så här kan du finjustera modellen:
- Finjustera med anpassade data:Träna modellen med dina egna ljud- och transkriptionsdatauppsättningar för att förbättra igenkänningen av specifika accenter eller branschtermer.
- Justera inferensinställningar:Ändra parametrar som temperatur och strålsökning för att förfina noggrannheten.
- Lägg till anpassat ordförråd:Lär modellen nya ord och fraser som är relevanta för din domän.
Anpassning gör modellen mer exakt och pålitlig för dina specifika behov. Men om du föredrar en enklare lösning, kolla in nästa avsnitt för ett enkelt alternativ till tal-till-text!
Del 3:Ett enklare alternativ:Automatisk tal-till-text med Filmora
Att krama Face Speech-to-Text verkar för komplicerat och kräver tekniska färdigheter som kodning. Men det finns ett enklare alternativ_ Wondershare Filmora är ett mycket enklare sätt att konvertera tal till text. Filmora är ett populärt videoredigeringsprogram som har ett tal-till-text-verktyg som automatiskt transkriberar ljud med några få klick.
- Filmora förenklar allt för dig. Så du behöver inga programmeringskunskaper eller komplicerade konfigurationer.
- Den kan transkribera videotal till text med upp till 99 % noggrannhet. Så innehållsskapare, studenter och till och med affärsmän kan använda det för att generera text från ljud snabbt och exakt.
- Stöder 45+ språk och fungerar bra för videoundertexter, röstanteckningar och intervjuer.
- Den är utrustad med automatisk undertextöversättning för flerspråkigt innehåll
- Du kan skapa anpassningsbara animerade bildtexter för att öka engagemanget
- Dessutom behandlar Filmoras inbyggda tal-till-text-funktion ljuddata mycket snabbt och sparar tid för användaren. Dess hastighet och tidsbesparande förmåga är det som gör det till det bästa alternativet.
Del 4:Hur man använder Filmora Speech-to-Text
Filmora gör det väldigt enkelt att konvertera tal till text. Det finns ingen anledning att skapa kod eller ställa in något svårt.
Följ bara dessa enkla instruktioner för att få din transkription på nolltid med hjälp av skrivbordet tal till text-funktionen:
Steg 1:Importera ditt ljud eller video
Öppna Filmora och lägg till din ljud- eller videofil. Du kan göra detta genom att helt enkelt dra och släppa det på tidslinjen. Detta gör det lättare för dig. När din fil är på plats är du redo att gå vidare.
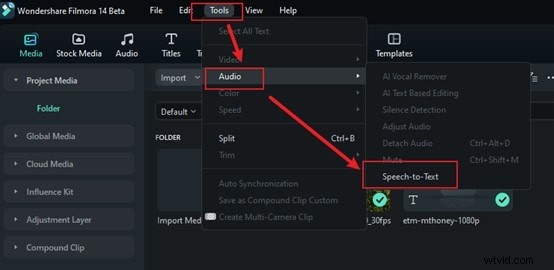
Steg 2:Välj alternativet Tal-till-text
Gå till Verktyg i den övre menyraden och klicka på den. Välj alternativet Ljud och sedan Text till tal för att automatiskt analysera ditt ljud. Du behöver inte justera inställningar eller göra något extra eftersom den hanterar allt åt dig.
Steg 3:Välj ditt språk
Filmora stöder många språk, så välj det som matchar ditt ljud. Det här steget är viktigt eftersom att välja rätt språk hjälper Filmora att transkribera ditt tal korrekt. Om du hoppar över detta kan du få felaktiga resultat.
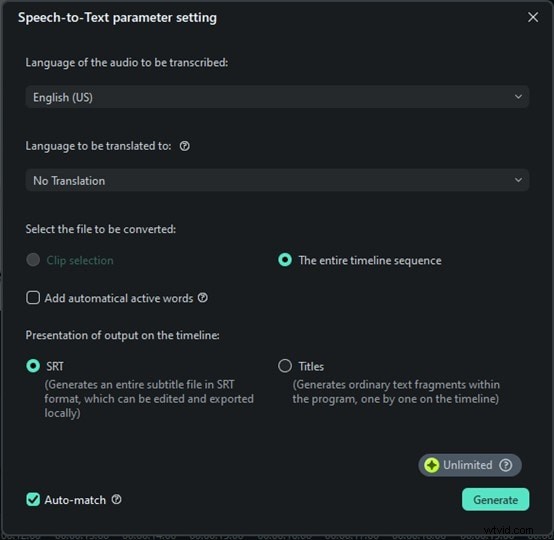
Steg 4:Starta transkriptionen och spara
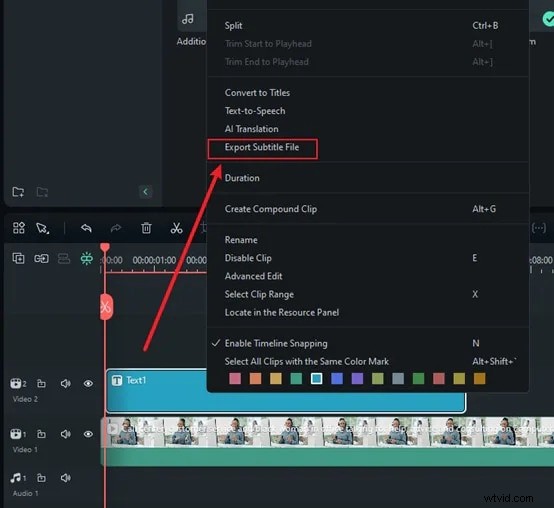
Nu klickar du bara på Generera så börjar Filmora transkribera ditt tal. Den här delen är riktigt snabb. Inom några sekunder kommer du att se de talade orden visas som text. Ingen väntan i timmar, ingen komplex installation, bara omedelbara resultat. Klicka på textfilen, välj Exportera undertextfil transkription för att spara den för att lägga till som undertexter till din video.
Om du vill konvertera videotal till texttexter erbjuder Filmora också en AI Captioning-funktion på sin mobilapp. Det låter dig skapa texttexter på din mobila enhet på mindre än en minut
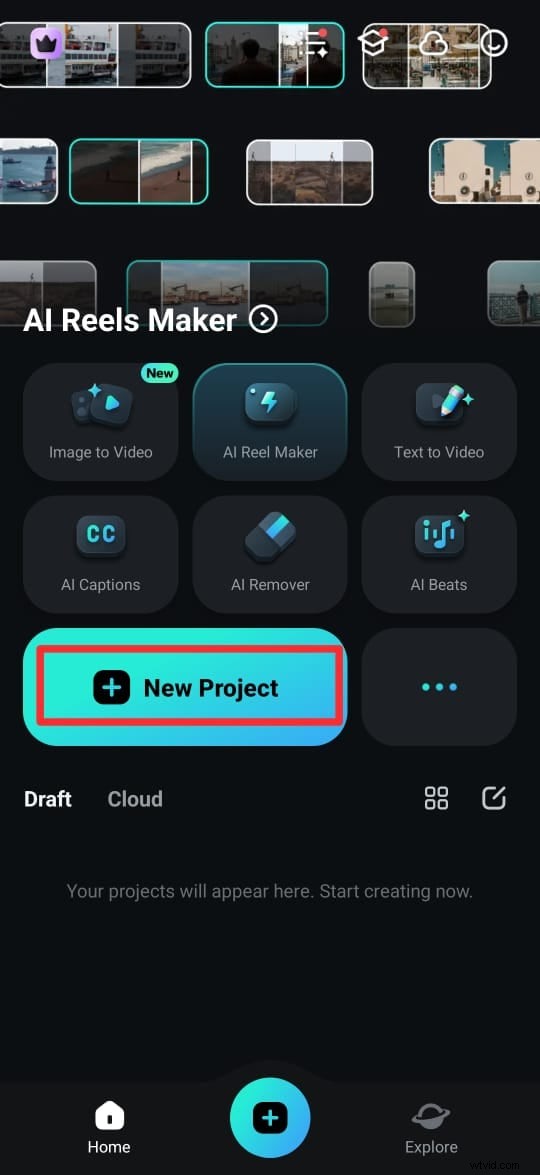
Steg 1:Ladda ner Filmora-appen från Google Play Store (Android) eller App Store (iPhone). Du kan också få det från den officiella webbplatsen. När den är installerad öppnar du appen och trycker på Nytt projekt.
Steg 2. Välj en video från ditt mediebibliotek och tryck på Importera för att lägga till den i din arbetsyta.

Steg 3:På den nedre menyn, tryck på Text (markerad med en T-ikon) och välj AI Captions.
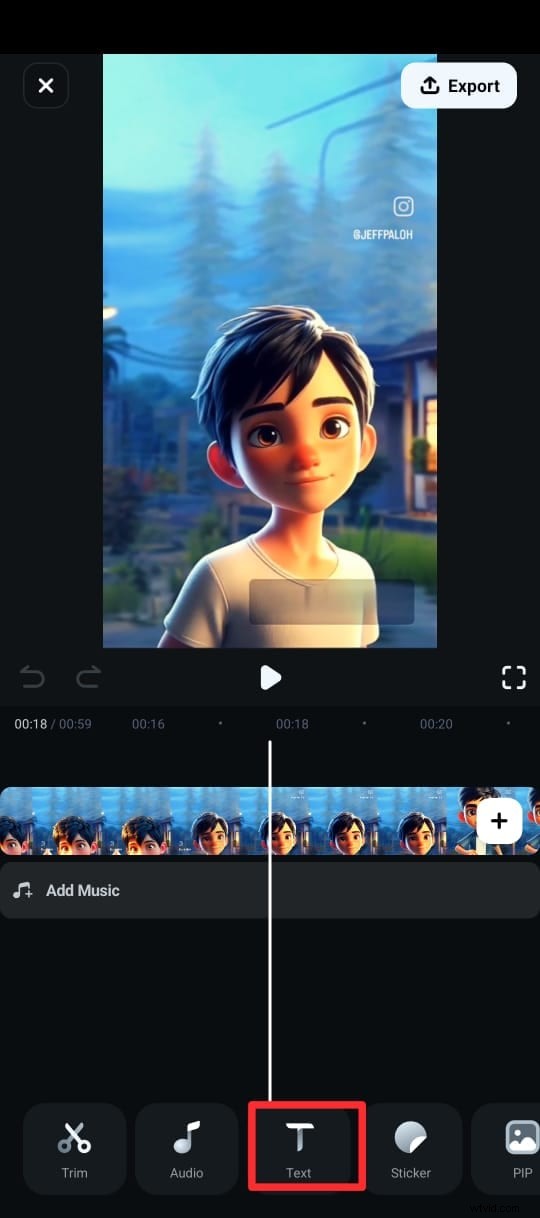
Steg 4:På nästa skärm väljer du språk, aktiverar Speaker Detection och trycker på Lägg till bildtexter för att generera text från videons tal.
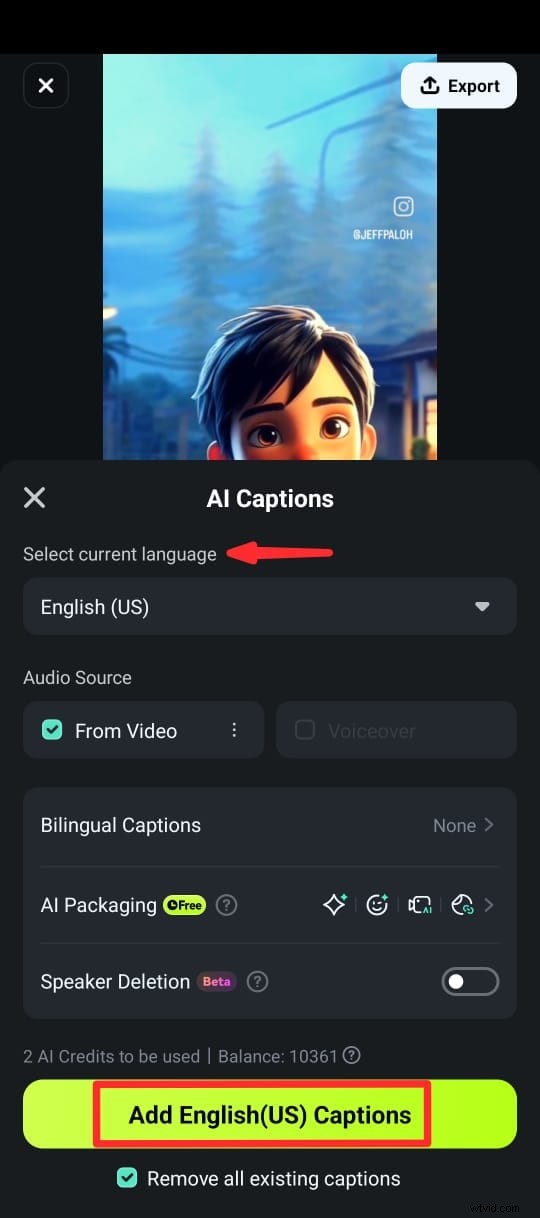
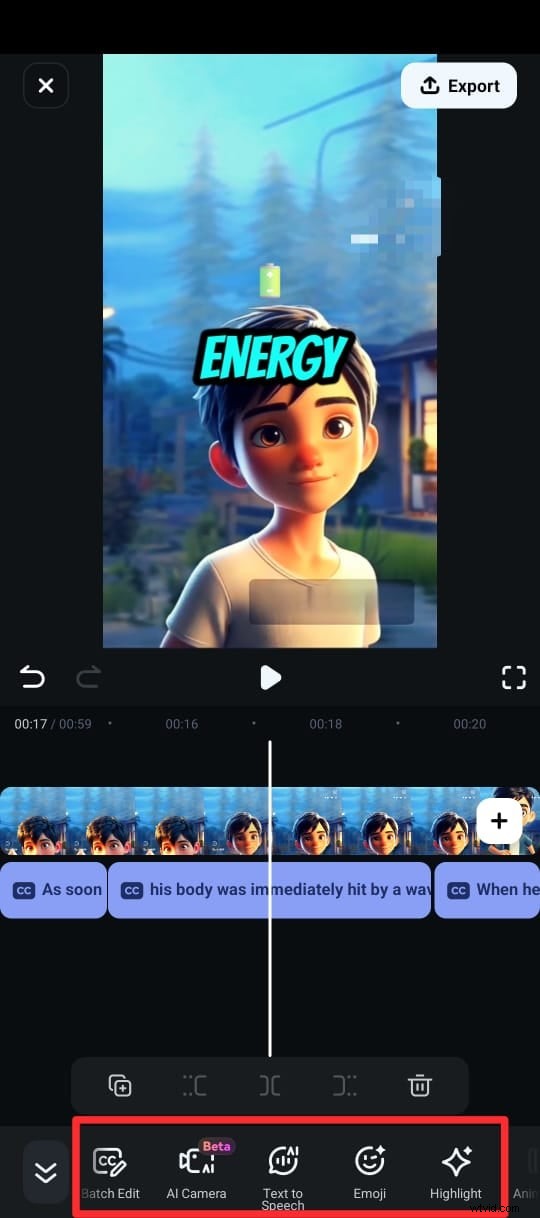
Steg 5:När bildtexterna har genererats kan du anpassa texten med hjälp av olika textmallar, emojis och typsnitt. Du kan också redigera texten i klippet på tidslinjen genom att välja Redigera tal från redigeringssviten.
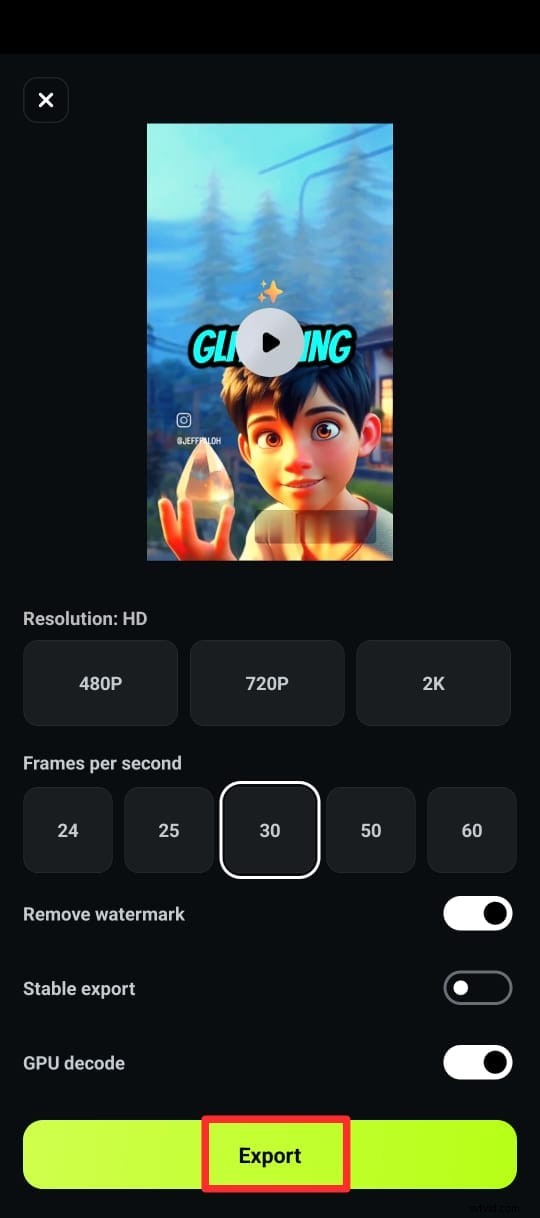
Steg 6:Exportera din video med textning i önskat format.
Del 5. Vilket verktyg är bäst?
Att välja mellan Hugging Face och Filmora beror på dina specifika behov och nivå av teknisk expertis. Varje verktyg har olika syften, så låt oss utforska vilket som är rätt för dig baserat på olika scenarier.
- Om du behöver avancerad anpassning och AI-driven kontroll är Hugging Face-tal till text det bättre valet. Den är idealisk för utvecklare, forskare och proffs som vill träna modeller, finjustera parametrar och arbeta med stora datamängder. Det kräver dock kunskap om kodning och tid att installera, vilket gör det mindre lämpligt för nybörjare eller de som letar efter en snabb lösning.
- Å andra sidan, om du vill ha ett snabbt, exakt transkriptionsverktyg utan någon teknisk installation, är Filmora rätt väg att gå. Den är utformad för innehållsskapare, studenter och proffs som behöver en enkel lösning med ett klick.
- Använd Filmora om du lägger till undertexter till videor, transkriberar föreläsningar eller konverterar tal till text för rapporter.
- För dem som arbetar inom nischområden som kräver domänspecifik taligenkänning, låter Hugging Face dig träna modellen i branschspecifik terminologi. Detta säkerställer bättre noggrannhet för komplex jargong, men återigen, det kräver ansträngning och tekniskt kunnande.
- Om ditt huvudmål är att transkribera videoinnehåll är Filmora ett bekvämare alternativ eftersom det snabbt konverterar tal till text, vilket gör det idealiskt för YouTubers, poddsändare och skapare av sociala medier.
Sammanfattningsvis, om du älskar kodning och vill ha full kontroll och anpassning, gå till text till tal i huggingface. Men om du vill ha ett enkelt och omedelbart transkriptionsverktyg är Filmora det perfekta valet. Välj den som bäst passar ditt arbetsflöde och din kompetensnivå.
Slutsats
Att konvertera tal till text behöver inte vara komplicerat. Kramning av ansikte text till tal är ett kraftfullt verktyg men kräver kodning och installation vilket är coolt för utvecklare. Men om du vill ha något snabbt och enkelt är Filmora det bästa alternativet. Med bara några klick kan du transkribera ljud utan ansträngning; ingen kodning, ingen stress. Varför spendera timmar på komplexa installationer? Prova Filmoras tal-till-text-funktion idag och konvertera ditt ljud till text på några sekunder