Du redigerar en video med flera talare, kanske en podcast eller en intervju. Att lägga till textning manuellt är tråkigt – du måste lyssna, skriva och synkronisera varje talat ord. Vad händer om din videoredigerare automatiskt kunde känna igen olika röster och generera bildtexter för varje högtalare? Det är där högtalarigenkänning i Python ändrar spelet.
Python är det bästa programmeringsspråket för att utveckla röstbaserade applikationer på grund av dess robusta bibliotek. Dessa bibliotek hjälper dig att implementera och distribuera modeller för talarigenkänning för talbearbetning, analys och talaridentifiering i realtid. Till exempel levererar Pico Voice Eagle SDK snabb och exakt högtalaridentifiering för AI-drivna applikationer.
Alternativt finns det videoredigeringsplattformar som integrerar artificiell intelligens för taligenkänning. De fungerar genom att skanna videons ljud, särskilja högtalare och generera synkroniserade bildtexter.
Den här guiden kommer att utforska hur man implementerar högtalaridentifiering i Python. Vi kommer också att titta på de bästa kodfria alternativen för enkel videotextning.

I den här artikeln
- Grundläggande för ljudbehandling
- Högtalaridentifiering i realtid med Picovoice Eagle SDK
- Finns det enklare sätt att utföra högtalarigenkänning?
- Var kan jag använda appar för högtalarigenkänning?
Del 1:Grunderna för ljudbehandling

Varje röstigenkänningssystem börjar med ljudbehandling. Ljud färdas som kontinuerliga analoga signaler, men datorer kräver digitala format. För att konvertera tal till data använder vi samplingshastigheter och ljudkodningstekniker.
En samplingshastighet definierar hur ofta ljud spelas in per sekund. Standarden för Python-högtalarigenkänning är 16 kHz, vilket säkerställer hög noggrannhet. Formatet på ljudfilen spelar också roll – WAV, MP3 och FLAC är vanliga alternativ, med WAV att föredra för maskininlärningsuppgifter.
Python förenklar högtalaridentifiering i realtid med specialiserade bibliotek som PyAudio och Picovoice Eagle SDK. Med hjälp av dessa verktyg kan utvecklare fånga, analysera och träna modeller för högtalaridentifiering i realtid i Python.
Del 2:Högtalaridentifiering i realtid med Picovoice Eagle SDK
Picovoice Eagle SDK är ett högpresterande verktyg för högtalarigenkänning i Python . Till skillnad från traditionella modeller bearbetar den ljud lokalt. Denna SDK är avgörande för högtalaridentifiering i realtid i Python, särskilt i AI-säkerhetssystem och smarta assistenter.
Dessutom är den lätt och fungerar sömlöst över flera plattformar, inklusive Windows, macOS, Linux, Android, iOS och till och med Raspberry Pi. Du behöver bara registrera dig för Pico Voice-konsolen och få din åtkomstnyckel för att autentisera din användning.
Installera och konfigurera Pico Voice Eagle SDK i Python
För att integrera Picovoice Eagle SDK för högtalarigenkänning i Python, installera det först. Innan du gör detta, se till att du har Python 3.6+ installerat.
Öppna en terminal (Linux/macOS) eller kommandotolken (Windows) och kör:
eller
Om Python är installerat kommer det att visa något i stil med:
Om versionen är 3.6 eller senare är du bra att gå.
För att börja, installera de nödvändiga biblioteken. Kör följande i din terminal:
pip installera SpeechRecognition pyaudio librosa pvrecorder
För Picovoice Eagle SDK, ladda ner och installera:
pip install pvporcupine pveagle
Steg-för-steg-guide för att implementera högtalaridentifiering i realtid med Picovoice Eagle SDK i Python
- Steg 1:Installera Python. På den officiella Python-webbplatsen väljer du alternativet för att ladda ner den senaste versionen, Python 3. x.x.
- Steg 2: Nästa, registrera dig för ett kostnadsfritt Picovoice Console-konto och hämta din åtkomstnyckel. Den här nyckeln krävs för att autentisera dina förfrågningar när du använder Eagle Speaker Recognition SDK.
- Steg 3: Installera de nödvändiga Python-paketen. Kör följande kommando i din terminal:
pip installera pveagle pvrecorder
Detta kommer att installera PV Eagle (för högtalarigenkänning) och PV-inspelare (för ljudinspelning).
- Steg 4: Skapa två filer i din VsCode. Den första filen kommer att vara att registrera en talare. Registrering är processen att skapa en högtalarprofil baserad på röstdata. Följ dessa steg:
- Importera de obligatoriska biblioteken
- Initiera EagleProfile med din åtkomstnyckel
- Använd PV-inspelare för att fånga röstprover
- Mata ljudramar till EagleProfile tills registreringen är klar
- Exportera högtalarprofilen för framtida igenkänning
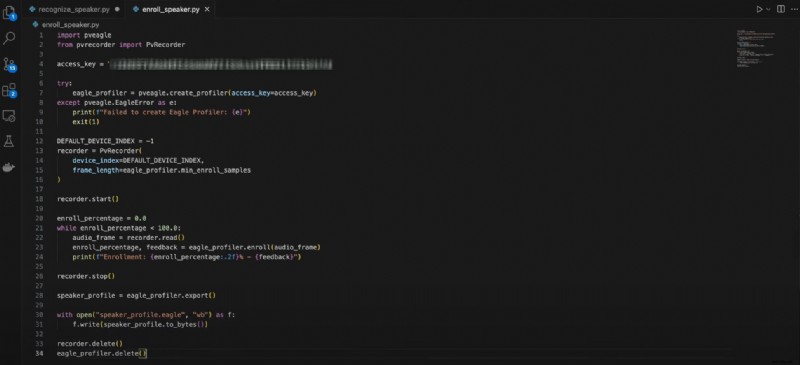
Här är koden för högtalarregistrering:
importera pveaglefrån pvrecorder import PvRecorder
access_key ="DIN_ACCESS_KEY"
försök:
eagle_profiler =pveagle.create_profiler(access_key=access_key)
förutom pveagle.EagleError som e:
print(f"Det gick inte att skapa Eagle Profiler:{e}")
exit(1)
DEFAULT_DEVICE_INDEX =-1
inspelare =PvRecorder(
device_index=DEFAULT_DEVICE_INDEX,
frame_length=eagle_profiler.min_enroll_samples
)
recorder.start()
enroll_procent =0,0
medan enroll_procent <100,0:
audio_frame =recorder.read()
enroll_percentage, feedback =eagle_profiler.enroll(audio_frame)
print(f"Enrollment:{enroll_percentage:.2f}% - {feedback}")
recorder.stop()
speaker_profile =eagle_profiler.export()
med open("speaker_profile.eagle", "wb") som f:
f.write(speaker_profile.to_bytes())
recorder.delete()
eagle_profiler.delete()
- Steg 5:Gå till din terminal och spela in genom att ange koden nedan
python3 enroll_speaker.py
När skriptet körs, försök att prata i mikrofonen. Om din röst matchar den registrerade högtalarprofilen kommer den att skriva ut "Högtalaren känns igen!" Annars kommer det att indikera en okänd talare.

- Steg 6: Nu när högtalarprofilen är klar, låt oss skapa en kod för högtalarigenkänning i realtid på den andra filen. Detta laddar en högtalarprofil och känner igen en högtalare i realtid med Pico Voice Eagle SDK.
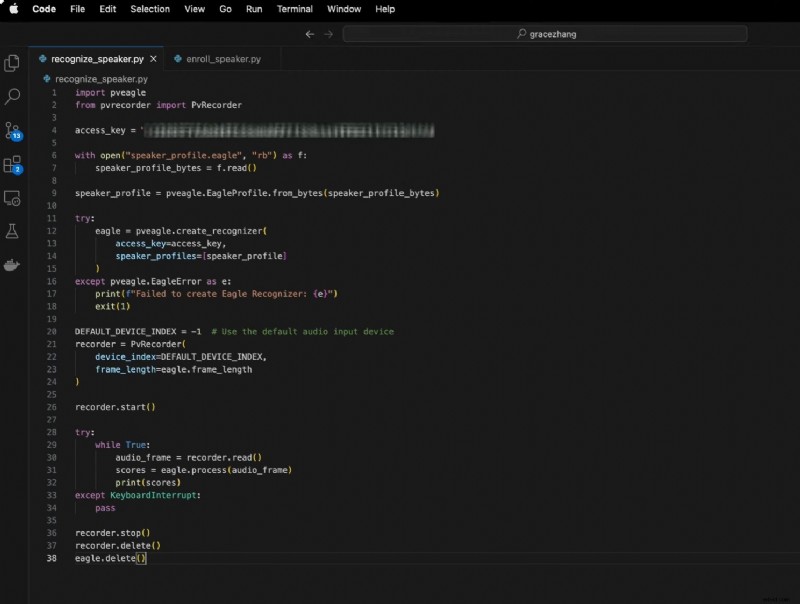
Detta innebär:
- Skapa en Eagle-instans med din åtkomstnyckel och högtalarprofil
- Använda PV-inspelare för att fånga liveljud
- Överför ljudramarna till Eagle för realtidsigenkänning
Här är koden:
importera pveaglefrån pvrecorder import PvRecorder
access_key ="DIN_ACCESS_KEY"
med open("speaker_profile.eagle", "rb") som f:
speaker_profile_bytes =f.read()
speaker_profile =pveagle.EagleProfile.from_bytes(speaker_profile_bytes)
försök:
eagle =pveagle.create_recognizer(
access_key=access_key,
speaker_profiles=[speaker_profile]
)
förutom pveagle.EagleError som e:
print(f"Det gick inte att skapa Eagle Recognizer:{e}")
exit(1)
DEFAULT_DEVICE_INDEX =-1 # Använd standardljudinmatningsenheten
inspelare =PvRecorder(
device_index=DEFAULT_DEVICE_INDEX,
frame_length=eagle.frame_length
)
recorder.start()
försök:
medan Sant:
audio_frame =recorder.read()
poäng =eagle.process(audio_frame)
print (poäng)
förutom tangentbordsavbrott:
passera
recorder.stop()
recorder.delete()
eagle.delete()
- Steg 7:Testa och kör programmet.
Python3 recognize_speaker.py
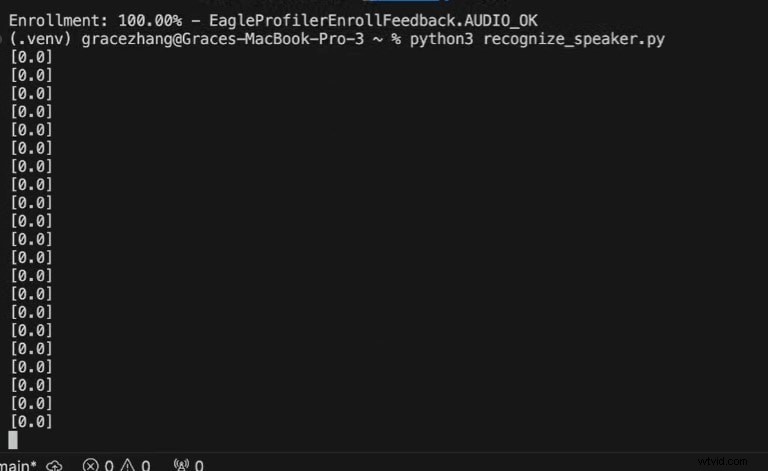
0 =Rösten känns inte igen
1 =Röst igenkänd

Obs:Till skillnad från molnbaserade modeller behandlar Picovoice Eagle SDK data lokalt. Detta säkerställer snabbare resultat, bättre sekretess och inget internetberoende.
Högtalaridentifiering i Python kan bara förstås och utföras av professionella programmerare. Du måste ha kunskap om programmering i viss mån för att förstå processen.
Del 3:Finns det enklare sätt att utföra högtalarigenkänning?
Att bygga ett Python-högtalarigenkänningssystem kräver kodningsfärdigheter och teknisk kunskap. Även om identifiering i Python är kraftfullt, kan det vara utmanande för icke-programmerare. Många användare föredrar färdiga verktyg som erbjuder liknande funktioner för högtalare och taligenkänning. Det är ett bättre sätt att få uppgiften gjord utan kodningsförmåga.
Ett sådant verktyg är WondershareFilmora, en videoredigerare med inbyggd högtalarigenkänning och talredigering. Det tillåter användare att upptäcka, transkribera och ändra röstinspelningar utan att skriva en enda rad kod.
Till skillnad från Python-högtalarigenkänning, som kräver manuell modellträning, automatiserar Filmoras inbyggda verktyg processen. Du kan redigera och förbättra ljudfiler utan att behöva kunskap om Python eller maskininlärning. Detta gör talaridentifiering tillgänglig för innehållsskapare, marknadsförare och företagsanvändare.
Filmoras mobilhögtalardetektering och talredigeringsfunktioner
Filmora integrerar ett AI-drivet verktyg som förenklar ljudredigering och högtalarigenkänning. Med sin mobila version kan användare få åtkomst till högtalardetektering och talredigeringsfunktioner.
- Högtalardetektering.Speaker Detection analyserar ljud och skiljer mellan olika högtalare. Istället för det manuella sättet att lyssna och tagga röster, identifierar AI vem som talar och när.
- Talredigering. Att redigera tal kan vara tråkigt, men Filmoras Speech Edit förenklar processen. Det tillåter användare att ändra röstinspelningar, justera klarheten och ta bort bakgrundsljud.
Hur man känner igen röst, konverterar till text och redigerar med Filmora på språng
Filmora gör högtalarigenkänning enkelt med några få klick. Här är en steg-för-steg-guide:
- Steg 1:Ladda ner Filmora, klicka på "nytt projekt och importera videon med rösten.
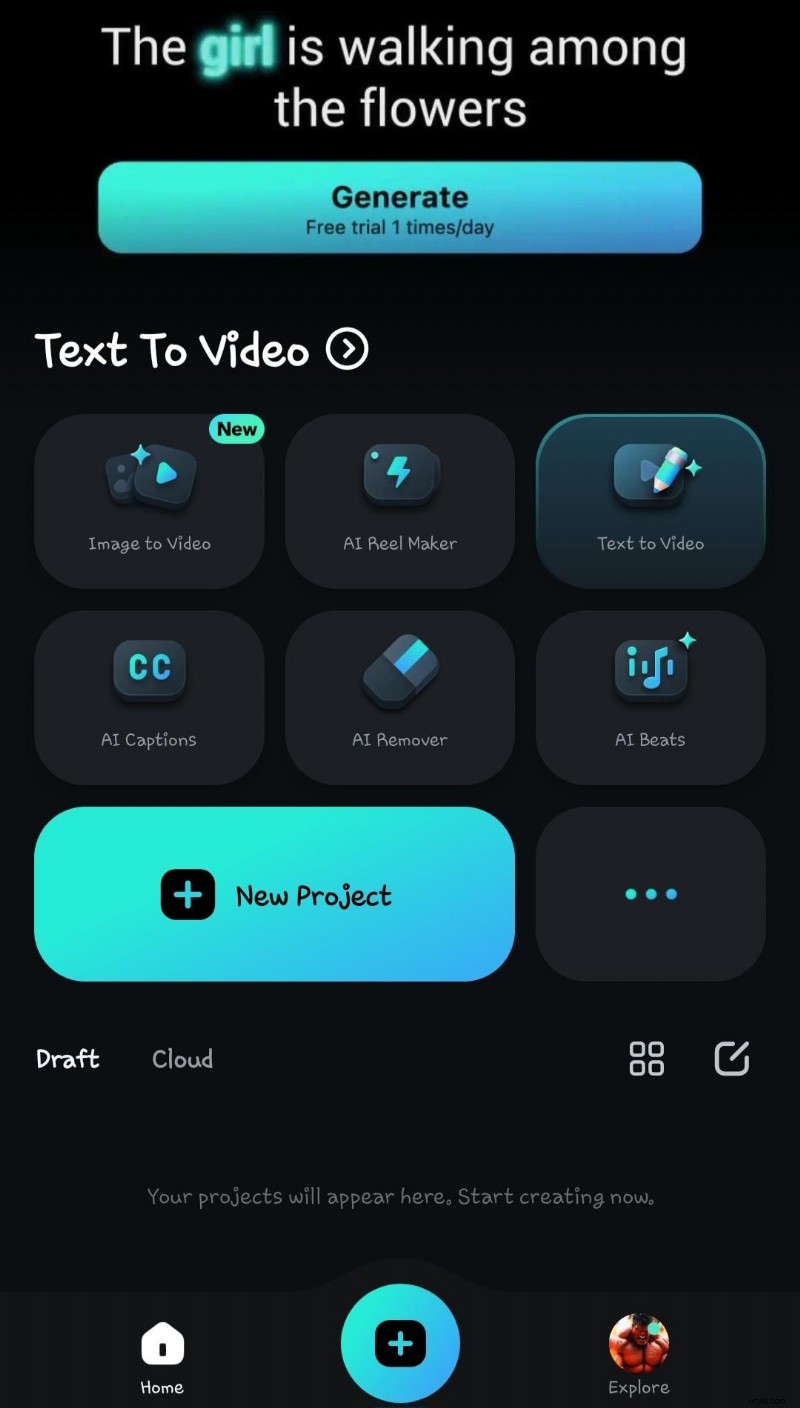
- Steg 2:Välj text för att konvertera de talade orden till text.

- Steg 3:Klicka på AI-textning för att starta röstigenkänningsprocessen
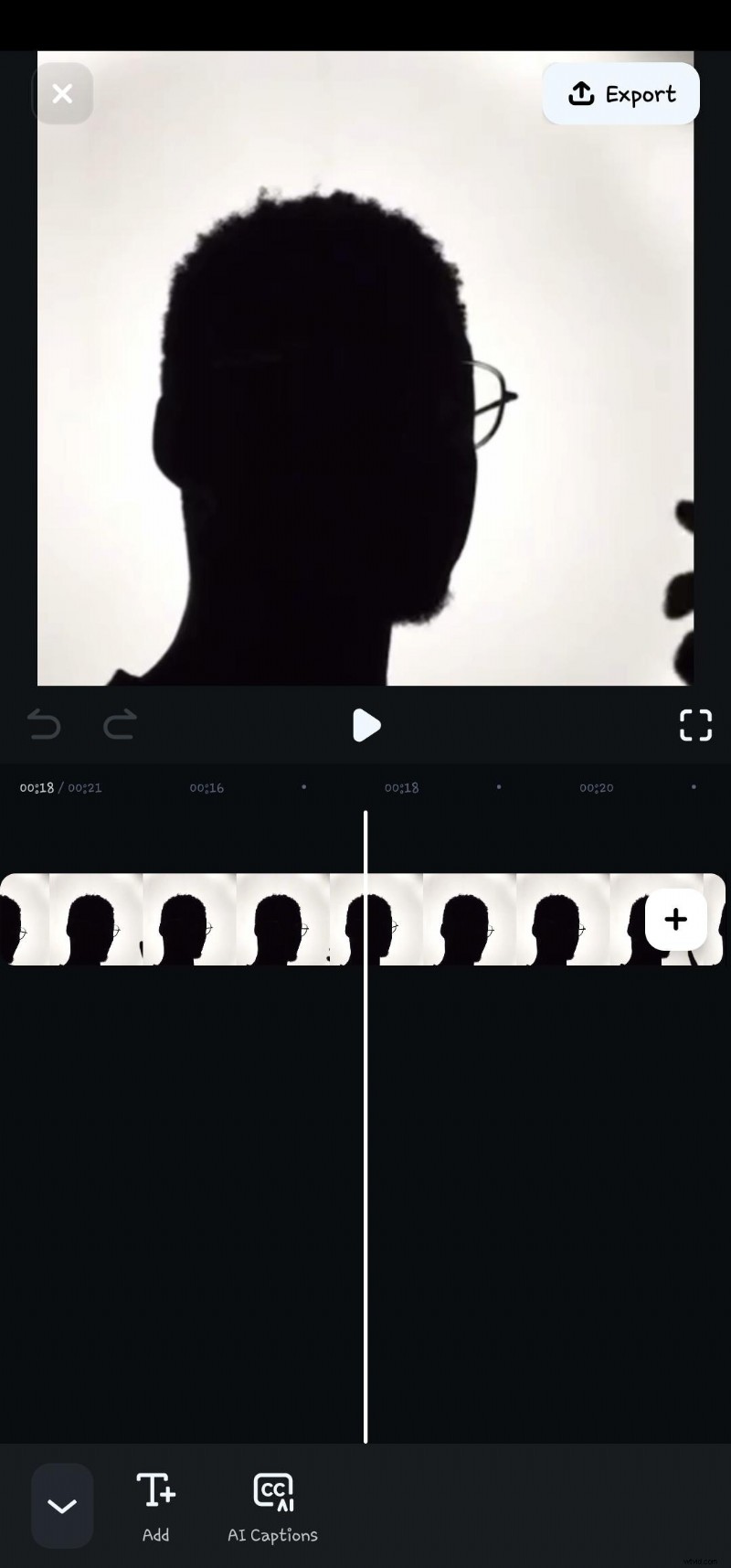
- Steg 4: Klicka på alternativet Speaker Detection innan du väljer Lägg till bildtexter
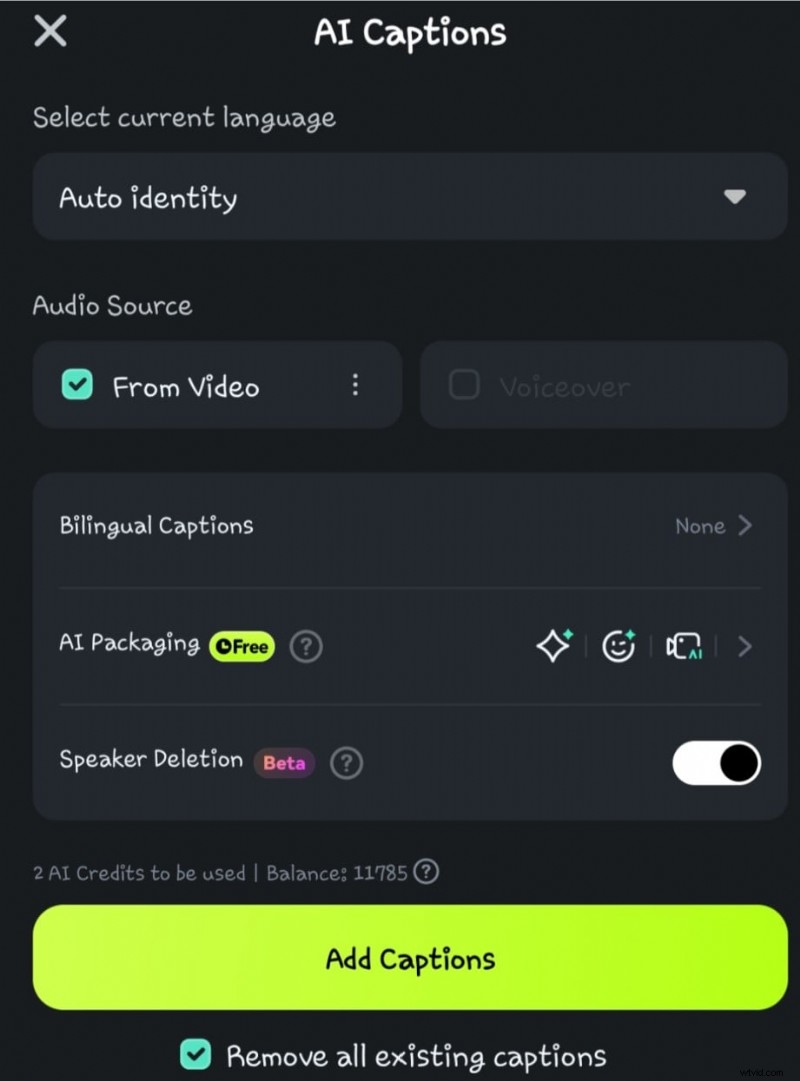
- Steg 5: Vänta medan AI:n bearbetar rösten till texten
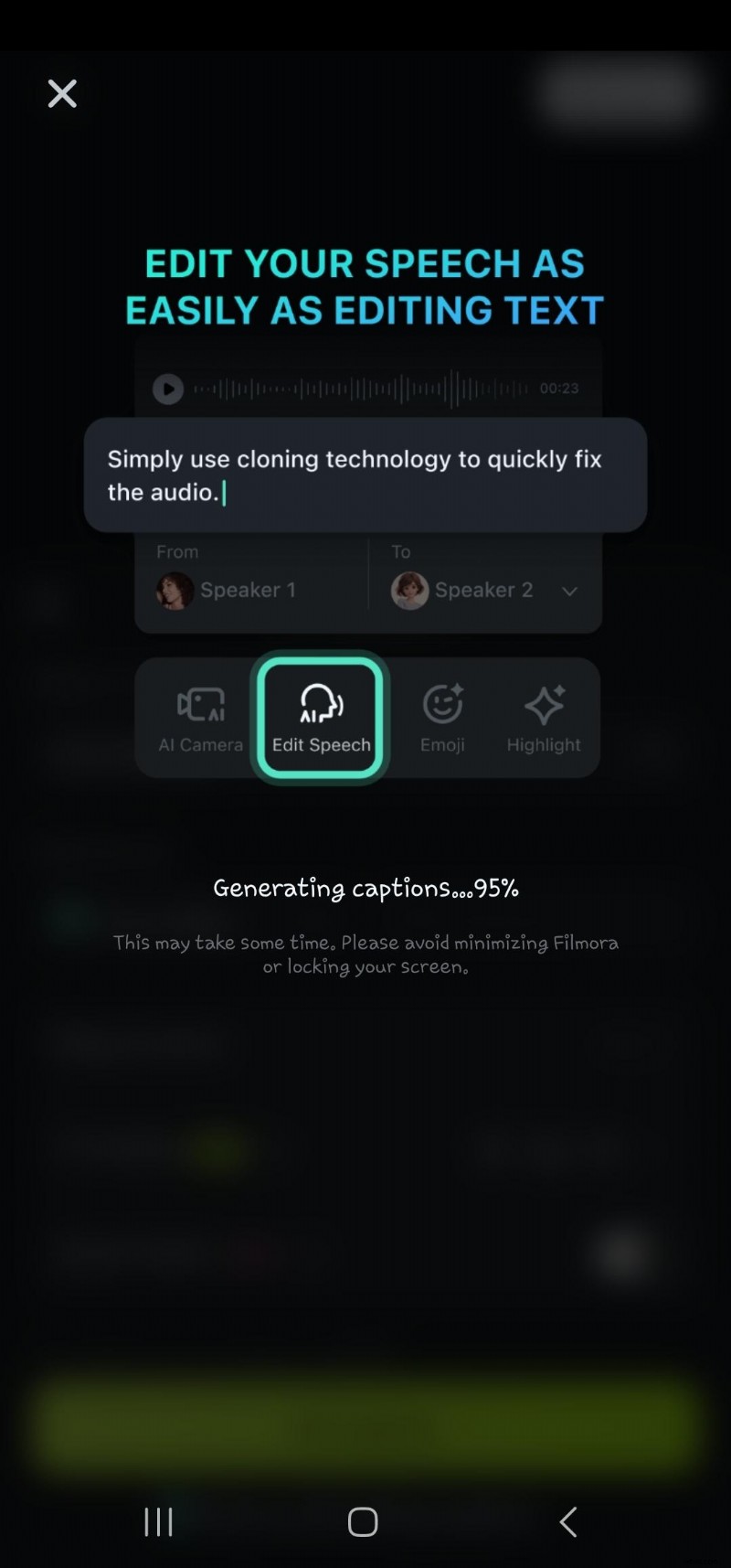
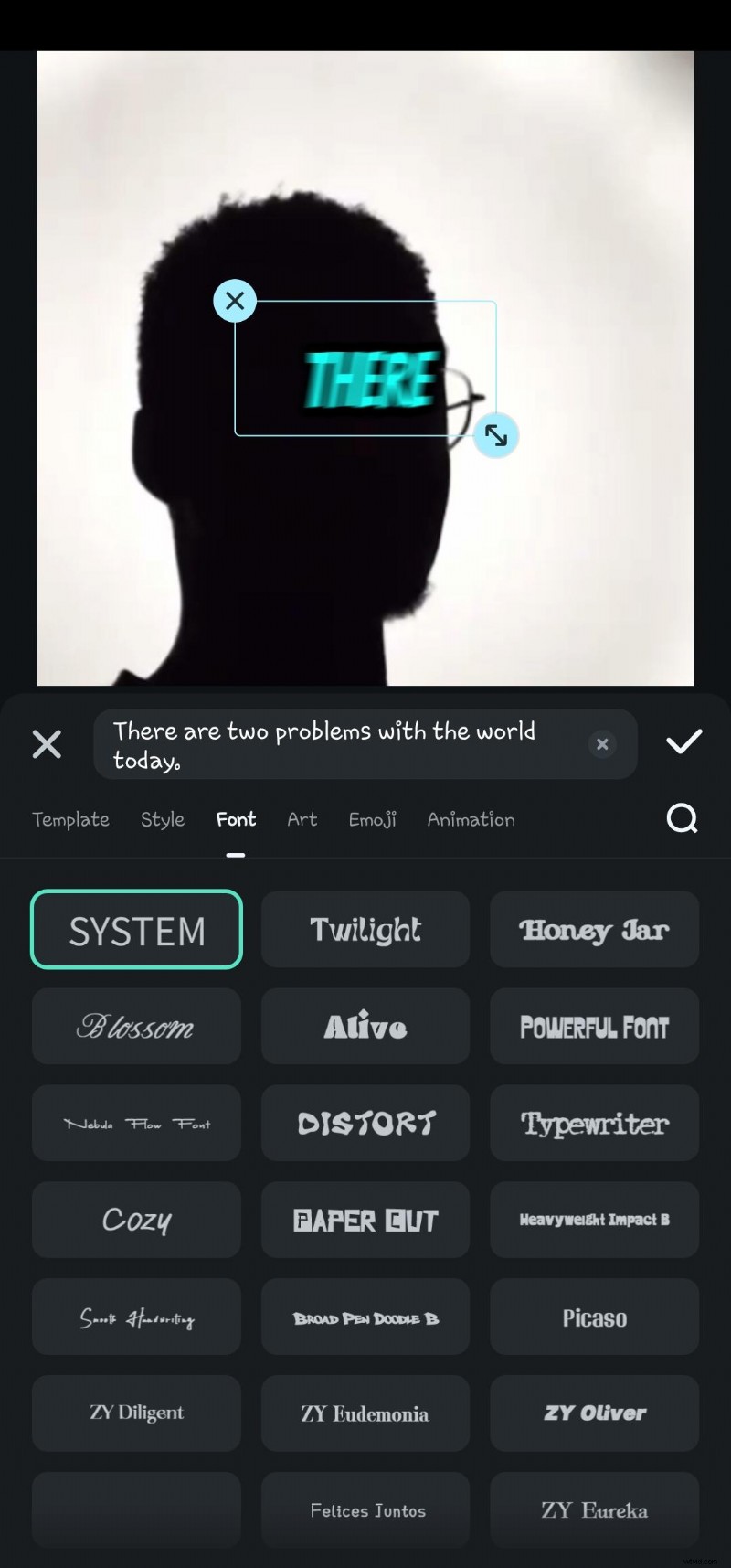
- Steg 6:Dubbelklicka på den genererade texten på tidslinjen för att navigera till alternativet för att redigera tal. Här kan du lägga till animationer, ändra textmall, typsnitt, stil, konst etc.
- Steg 7:Exportera videon
Obs! Du måste förstå att Python-högtalarigenkänning ger full kontroll över modellträning. Men Filmora erbjuder ett automatiserat tillvägagångssätt. Dess AI-funktion säkerställer effektiv högtalarigenkänning utan komplexiteten med programmering.
Del 4:Var kan jag använda appar för högtalarigenkänning?

Högtalarigenkänning i Python förvandlar olika branscher, utan tvekan. Denna teknik ger ett snabbt och tillförlitligt sätt att identifiera röster i videor eller ljudfiler. Det håller på att bli en grundläggande del av olika branscher. Nedan finns områden där dessa appar är tillämpliga.
- Smarta assistenter och röststyrda enheter. Appar som Siri, Alexa och Google Assistant använder högtalaridentifiering för att skilja röster. Detta möjliggör personliga svar, säker åtkomst och anpassade röstkommandon för olika användare.
- Säkerhet och röstautentisering. Många företag använder högtalaridentifiering för att verifiera användare och förhindra bedrägerier. Det eliminerar lösenordsberoende samtidigt som dataskyddet och användarvänligheten förbättras.
- AI-driven transkription och mötesanteckningar. Högtalarigenkänning hjälper applikationer som Otter.ai att skilja högtalare åt. Detta ökar noggrannheten i transkriptionen, särskilt de med flera röstanteckningar.
- Callcenter och kundsupport. Callcenter använder högtalarigenkänning i Python för att förbättra kundautentisering och upptäckt. AI-drivna system identifierar uppringare med röst, vilket minskar behovet av manuell identitetsverifiering. Detta förbättrar säkerheten, effektiviteten och svarstiderna i kundtjänsten.
- Hälsovård och tillgänglighet. Sjukhus och vårdappar använder högtalaridentifiering för säker patientautentisering. Röstbaserade AI-verktyg hjälper individer med begränsad rörlighet åtkomst till enheter utan fysisk interaktion. Python-högtalarigenkänning garanterar säker medicinsk åtkomst och förbättrar patientvården.
Slutsats
Python är ett av de mest populära språken för talare och röstidentifiering. Det tillhandahåller kraftfulla bibliotek som SpeechRecognition, PyAudio, Librosa och Pico Voice Eagle SDK.
Dessa verktyg möjliggör hög noggrannhet och högtalaridentifiering i realtid i Python . Detta gör det till det bästa alternativet för utvecklare, AI-forskare och säkerhetsapplikationer. Filmora erbjuder ett enklare alternativ för dem utan programmeringskunskaper. Det ger tal-till-text-konvertering, röstredigering och högtalarigenkänning utan att Python-kodning krävs.
Prova Filmoras AI-drivna verktyg för automatisk röstredigering och transkription. De gör processen snabb och vänlig.

Filmora
⭐⭐⭐⭐⭐
Den bästa AI-drivna programvaran och appen för videoredigering