OpenAI:s GPT-Image2, släppt april 212026, är företagets nyaste bildmodell och efterföljaren till DALL-E. Det introducerar ett paradigmskifte:bilder genereras inte längre av en diffusionsprocess utan av ett autoregressivt system som tänker, planerar och verifierar innan det ritar. Resultatet är en modell som ger realistiska bilder, flytande flerspråkig text och ett inbyggt resonemangslager som skiljer den från alla andra AI-bildgeneratorer på marknaden.
Snabb genomgång
- GPT-Image2 är nu OpenAI:s enda bildmodell, efter att DALL-E2 och 3 gick i pension i maj 122026.
- Dess autoregressiva arkitektur speglar textgenereringslogiken som används i GPT‑4o, vilket ger en konsekvent pipeline för pixlar och ord.
- Textnoggrannheten har ökat till 99 % på engelska och över 90 % på kinesiska, japanska, koreanska, hindi, bengali och arabiska.
- Modellen kan planera layouter, hämta data från webben och självverifiera resultat innan bilden slutförs.
- Bildkvoterna sträcker sig från 3:1 till 1:3, med inbyggt stöd för 16:9 och 9:16. Standardutgången är 2K; 4K är tillgängligt i API-betan.
- Den här artikeln förklarar det arkitektoniska skiftet, de fem mest effektfulla funktionerna, dess begränsningar, en jämförelse med Midjourney, FLUX och Nano Banana2 och hur man bäddar in det i ett bredare arbetsflöde med InVideo.
Vad är ChatGPT Images2.0?
GPT-Image2 representerar mer än skarpare utdata; den beter sig som en kreativ partner. Istället för att översätta uppmaningar rakt till pixlar tolkar modellen avsikten, planerar kompositionen och förfinar den slutliga bilden. Den är tillgänglig inom ChatGPT och genom OpenAI API, placerad som en tillgångsgenerator i produktionsklass för riktiga designarbetsflöden.
Hur GPT-Image2 kan förändra ditt kreativa arbetsflöde
1. Korrekt text i ett pass
Med 99 % textnoggrannhet återges rubriker, underrubriker och uppmaningar korrekt vid första försöket – inga Photoshop-rundturer eller designerredigeringar krävs. Ett DTC-varumärke kan generera tio annonsvarianter, var och en med unik kopia, och skicka de slutliga tillgångarna direkt.

2. Produktförpackningar och etikettmodeller
Varumärkeskopia på en etikett är inte längre en svag punkt. GPT-Image2 stavar exakt produktnamn och taglines på flera språk – mandarin, hindi, japanska, koreanska och arabiska – så globala varumärken kan lansera bilder som matchar deras kopia från dag ett.

3. Sociala tillgångar i alla format
Bildförhållanden sträcker sig nu från 3:1 till 1:3, inklusive inbyggda 16:9 och 9:16. En enda uppmaning kan producera en YouTube-miniatyrbild, Instagram Story, LinkedIn-banner och karusellbilder utan att beskäras.

YouTube-miniatyr

Instagram-omslag

Karusellbilder
4. Infografik på ett enkelt sätt
Täta layouter förblir sammanhängande. Flera datapunkter, etiketter och rubriker förblir där du placerar dem, vilket gör att B2B-varumärken kan konvertera statistiktunga rapporter till ren, varumärkesinfografik utan att lämna över till en designer.

5. Konsekventa karaktärer, miljöer och illustrationer
Från spelkaraktärer till varumärkesmaskotar, GPT-Image2 kan skapa unika personligheter, fantasivärldar, futuristiska städer och historiska miljöer – allt samtidigt som den visuella konsekvensen över scenerna bibehålls.



Författare, serieskapare och utgivare kan använda GPT-Image2 för att visualisera narrativa beats och experimentera med visuellt berättande.


6. Användargränssnitt och konceptmodeller
Med starka instruktioner som följer, producerar GPT-Image2 rena UI-mockups från en enkel skärmbeskrivning. Produktteam kan lämna ut resultatet till utvecklare eller intressenter för sign-off.
7. Redaktionella omslag och layouter
Tidskriftsomslag och boklayouter drar nytta av snabb konceptutforskning. AI-genererade bilder kan ge omslagsberättelser liv på unika sätt, medan redaktionella illustrationer bibehåller en konsekvent visuell stil på alla sidor.



Där GPT-Image2 fortfarande faller kort
- Överföring av sessioner kan orsaka brus; starta om sessioner mellan batcher för optimal kvalitet.
- Upprepad affischgenerering kan konvergera till en enda stil – variera uppmaningar med tydliga stildirektiv för att upprätthålla mångfald.
- Fysik, strukturell noggrannhet, tekniska data, närbilder och text på böjda eller branta ytor är fortfarande utmanande. Behandla utdata som en solid utgångspunkt som fortfarande kräver mänsklig granskning.

De fem bästa funktionerna som skiljer GPT-Image2 åt
1. Inbyggt resonemang
Innan man ritar en pixel analyserar modellen prompten, planerar sammansättning, hämtar extern data och verifierar sin egen utdata – vilket speglar resonemanget i OpenAI:s textmodeller.
2. 99 % textåtergivningsnoggrannhet
GPT-Image1.5 erbjöd 90–95 % noggrannhet; GPT-Image2 hävdar 99 % för latinska och CJK-skript, vilket gör engångsutdata publicerbara utan ytterligare redigering.
3. Flerspråkig support
Kinesiska, japanska (Kanji &Hiragana), koreanska, hindi, bengali och arabiska återges alla korrekt, vilket låser upp marknader som tidigare modeller inte kunde betjäna.
4. Hög upplösning och flexibla bildförhållanden
Standardutgången är 2K (2048px). 4K är i API beta. Bildförhållande inkluderar nu 3:1 till 1:3, ursprungligt 16:9/9:16 och kvadrat – vilket eliminerar behovet av beskärning.
5. Stark instruktionsföljning och sammansättningskontroll
Rumsliga kommandon ("tre identiska robotar i rad"), uppmaningar med flera redigeringar och namnmanipulering av objekt fungerar på ett tillförlitligt sätt, vilket gör att täta kompositioner, infografik, serier och tidningsuppslag förblir sammanhängande.
GPT-Image2 vs. Midjourney, Nano Banana2 och FLUX
| Modell | Bäst för | Begränsning |
|---|---|---|
| GPT‑Image2 | Tunga bilder, flerspråkig text, layout-precis arbete, instruktionsföljande, konsistens i flera bilder | Fysik och 3D-text behöver fortfarande mänsklig granskning; mindre ekosystem |
| Midjourneyv8 | Ren visuell estetik – redaktionellt, filmiskt, stildrivet arbete | Inget offentligt API; icke-latinsk text otillförlitlig |
| Nano Banana2 | Högvolym, kostnadskänsliga arbetsflöden | Mindre precision på tät text och komplexa layouter |
| FLUX (Black Forest Labs) | Självhotell, finjustering, öppenviktslicenser | Mindre ekosystem, mindre distribution |
Vi körde en enda prompt genom alla fyra modellerna och jämförde resultaten sida vid sida.
Prompt: "Create a premium YouTube thumbnail in a modern AI‑tech editorial style. Split the composition into two contrasting halves. On the left side, showcase stunning AI‑generated visuals emerging from a glowing ChatGPT‑inspired interface: cinematic portraits, realistic product photography, vibrant illustrations, and professional marketing creatives. Use bright lighting, vibrant colors, futuristic UI elements, and upward arrows to symbolize benefits and innovation. On the right side, depict the limitations and challenges of AI image generation: distorted hands, inconsistent text rendering, failed generations, quality issues, and warning symbols. Use darker tones, subtle glitch effects, red highlights, and broken image frames to create contrast. In the center, feature a large glowing AI image‑generation panel with an image transforming from rough concept to polished masterpiece. Add dynamic particles, depth, dramatic lighting, and premium tech aesthetics. Large bold headline text: Here’s EVERYTHING YOU NEED TO KNOW ABOUT CHATGPT IMAGES 2.0. Secondary text: BENEFITS vs FALLBACKS Typography should be huge, bold, modern sans‑serif, highly readable at mobile size. Use white text with subtle shadows and cyan accents. Maintain strong visual hierarchy similar to top‑performing AI and technology YouTube thumbnails. Ultra‑sharp, high contrast, professional, viral‑worthy, clean composition, 16:9 aspect ratio."
Åtkomst till GPT-Image2
I ChatGPT
Generering av basbild är gratis för alla användare. Att välja en Thinking- eller Pro-modell låser upp resonemangslagret:webbsökning i realtid under generering, upp till tio bilder samtidigt och kontinuitet för karaktär/objekt över dem.
I InVideo (med kontextbevarande)
Autopilot
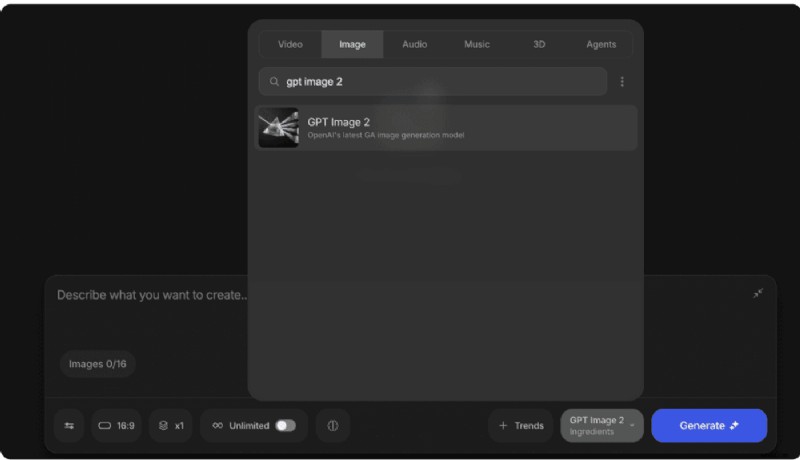
- Steg 1: Öppna Agents &Models, välj GPT-Image2.
- Steg 2: Skriv din uppmaning, ställ in upplösning och varianter och generera.
AgentOne
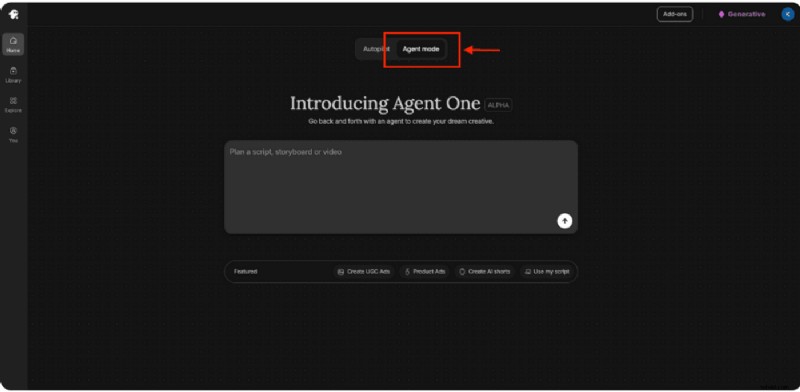
AgentOne kräver bara ett steg:beskriv vad du behöver på ett enkelt språk, och låt det skapa uppmaningen, idén och producera varianter – allt samtidigt som du bevarar ditt varumärke och din scenkontext.
Vanliga frågor
-
Vad är ChatGPT Images2.0?
GPT-Image2 är OpenAI:s nyaste bildgenerationsmodell, lanserad i april 212026. Den ersätter den äldre GPT-bildpipelinen och blir den enda bildmodellen efter att DALL-E2 och 3 avvecklas 122026 maj.
-
Hur använder jag ChatGPT Images2.0?
Du kan skapa bilder direkt i ChatGPT eller via InVideo. I InVideo öppnar du Agents &Models, väljer GPT-Image2, skriver en prompt, ställer in upplösning och variationer och genererar. Ditt varumärkeskontext bevaras över generationer.
-
Vilken är den största förbättringen jämfört med GPT-Image1.5?
Textåtergivningens noggrannhet hoppade från ~90–95 % till 99 %, vilket möjliggör enkelpassageaffischer, annonser, förpackningar, menyer och UI-modeller som är redo för produktion.
-
Stöder ChatGPT Images2.0 olika bildförhållanden?
Ja. Spänner från 3:1 (ultrabred) till 1:3 (hög vertikal), inklusive inbyggda 16:9 och 9:16 plus kvadrat. Standardutgången är 2K; 4K är tillgängligt i API-betan.
-
Kan GPT-Image2 generera text på andra språk?
Ja. Det återger kinesiska, japanska, koreanska, hindi, bengaliska och arabiska, vilket öppnar marknader som tidigare modeller inte kunde betjäna.
-
Var kommer ChatGPT Images2.0 fortfarande till korta?
Den kämpar med fysik, strukturell noggrannhet, tekniska data, närbilder och text på krökta eller brant vinklade ytor. Mänsklig granskning är fortfarande att rekommendera för produktionsarbete.
-
Är ChatGPT Images2.0 bättre än Midjourney?
Det beror på uppgiften. GPT-Image2 utmärker sig när det gäller textnoggrannhet, layouttunga tillgångar, flerspråkig rendering och instruktioner att följa. Midjourney kan leda på ren visuell stil.
-
Är GPT-Image2 en stor uppdatering?
Ja. Det är OpenAI:s tredje bildmodell på tretton månader, byggd om från grunden med en ny arkitektur. DALL-E2 och3 håller på att pensioneras, vilket gör GPT-Image2 till den enda bildmodellen som går framåt.
-
Hur uppnår GPT-Image2 korrekt text?
Tidigare modeller lärde sig visuella mönster av text; GPT-Image2 är autoregressiv och genererar texttokens som språk, vilket säkerställer semantisk noggrannhet. Denna förändring ökar textnoggrannheten från 90–95 % till 99 %.